
Improve your disaster recovery reliability with Veeam
The only two certainties in life are death and taxes. In IT, you can add disasters to this short list of life’s universal anxieties. Ensuring disaster recovery reliability is critical to ensure your organisations enduring viability in your chosen marketplace.
Regardless of the size of your budget, people power and level of IT acumen, you will experience application downtime at some point. Amazon’s recent east coast outage is testimony to the fact that even the best and brightest occasionally stumble.
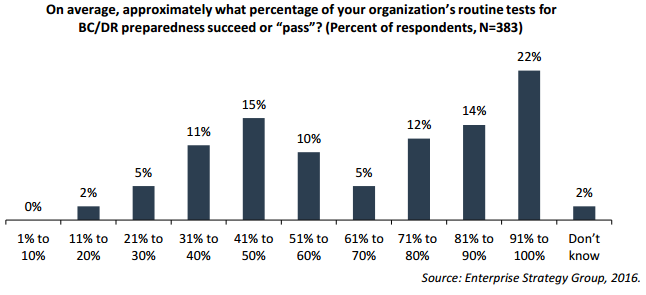
The irony is that while many organizations make significant investments in their disaster recovery (DR) capabilities, most have a mixed track record, at best, with meeting their recovery service level agreements (SLAs). As this chart from ESG illustrates, only 65% of business continuity (BC) and DR tests are deemed successful.
In his report, “The Evolving Business Continuity and Disaster Recovery Landscape,” Jason Buffington broke down respondents to his DR survey into two camps: “green check markers” and “red x’ers.”
Citing his research, Jason recently shared with me: “Green Checkers assuredly don’t test as thoroughly, thus resulting in a higher passing rate during tests, but failures when they need it most — whereas Red X’ers are likely get a lower passing rate (because they are intentionally looking for what can be improved), thereby assuring a more likely successful recovery when it really matters. One of the reasons for lighter testing is seeking the easy route — the other is the cumbersomeness of testing. If it wasn’t cumbersome, most of us would likely test more.”
DR testing can indeed be cumbersome. In addition to being time consuming, it can also be costly and fraught with risk. The risk of inadvertently taking down a production system during a DR drill is incentive enough to keep testing to a minimum.
But what if there was a cost-effective way to do DR testing that mitigates risk and dramatically reduces the preparation work and the time required to test the recoverability of critical application services?
By taking the risk, cost and hassle out of testing application recoverability, Veeam’s On-Demand Sandbox for Storage Snapshots feature is a great way for organizations to leverage their existing investments in NetApp, Nimble Storage, Dell EMC and Hewlett Packard Enterprise (HPE) Storage to attain the following three business benefits:
- Risk mitigation: Many IT decision makers have expressed concerns around their ability to meet end-user SLAs. By enabling organizations to rapidly spin-up virtual test labs that are completely isolated from production, businesses can safely test their application recoverability and proactively address any of their DR vulnerabilities.
- Improved ROI: In addition to on-demand DR testing, Veeam can also be utilized to instantly stand-up test/dev environments on a near real-time copy of production data to help accelerate application development cycles. This helps to improve time-to-market while delivering a higher return on your storage investments.
- Maintain compliance: Veeam’s integration with modern storage enables organizations to achieve recovery time and point objectives (RTPO) of under 15 minutes for all applications and data. Imagine showing your IT auditor in real-time how quickly you can recover critical business services. For many firms, this capability alone would pay for itself many times over.
Back when I was in school, 65% was considered a passing grade. In the business world, a 65% DR success grade is literally flirting with disaster. DR proficiency may require lots of practice but it also requires Availability software, like Veeam’s, that works hand-in-glove with your storage infrastructure to make application recoveries simpler, more predictable and less risky.
This article was provided by our service partner Veeam.