Veeam Cloud Tier
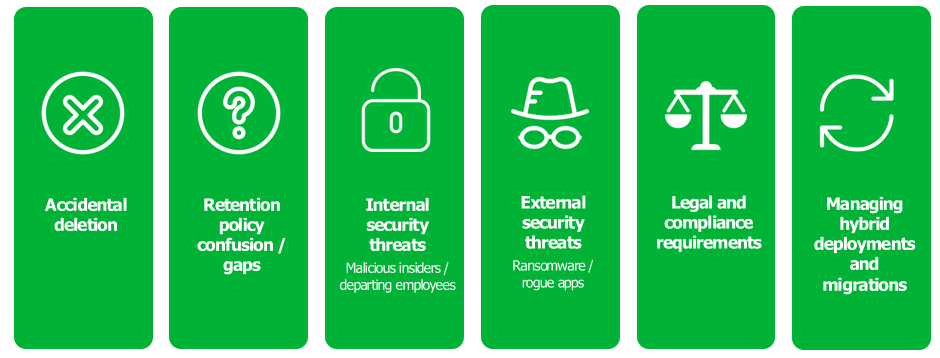
Data is growing faster and is more important than ever! All organization are experiencing explosive data growth and it’s becoming more and more apparent that the data being generated and protected is critical. Company viability is jeopardized when data is at risk and without secure and protected access to critical data, organizations face potential collapse. While the threat of a malicious attack against organizational data is not new, the methods and vectors of attack have evolved, and attacks have drastically increased in recent years.
Attacks on your data are at an all-time high! Ransomware is more powerful than ever, and corporations face an increased number of malicious attacks including both external and internal threats due to the era of connected platforms. The threat to data is real, and as part of an overall data management strategy leveraging new technologies is critical to protecting that data and ensuring that organizations are protected from malicious intent where data is either permanently deleted or held for ransom.
The storage landscape has fundamentally changed with Object Storage. With the release of Veeam Backup & Replication 9.5 Update 4 in 2019, we introduced the Veeam Cloud Tier which enabled customers to take advantage of Object Storage. Due to its increasing popularity, infinite scale-out capacity and lower cost for long term retention, Object Storage offers many advantages over traditional block and file-based storage systems. With regards to increasing amounts of backup data, and requirements to keep that data for longer periods of time, Object Storage is a perfect fit. Veeam has witnessed an overwhelming adoption of Object Storage with over 100PB of data offloaded to just a few top cloud object storage providers alone, despite the fact that in Update 4, the Cloud Tier was only capable of offloading older data to help to reduce the costs of long-term archival. This was just step 1, and now v10 brings more!
Introducing the next iteration of Veeam Cloud Tier in v10
With the launch of Veeam Backup & Replication v10 we have made drastic improvements. In v10, the Cloud Tier feature set has been extended to include three distinct, but very interconnected customer needs:
- Achieving the 3-2-1 rule and performing off-site backup in a fast, effective and automated fashion, thus lowering off-site RPOs
- Protecting your data from attacks by malicious insiders and hackers
- Simplifying recovery from a major disaster
Let’s dive into each of these customer needs further.
Copy Policy: Makes 3-2-1 easier than ever
Building on the “Move Policy” in Update 4, Copy Policy allows backup data to be instantly copied to the SOBR Capacity Tier as it’s created. This is an important distinction from what Move Policy does, where there is only ever one copy of the data sitting either in Performance Tier or Capacity Tier, which can leave recent restore points within the Operational Restore Window at risk in the case of disaster or malicious intent.
With Copy Policy enabled on a SOBR, all backup files that are created are effectively duplicated as soon as they are created to the Capacity Tier. This allows us to adhere to the 3-2-1 rule (3 copies of backup, on 2 different media, with 1 offsite) of backup that requires one independent copy of data offsite. In fact, when using cloud object storage, it allows customers to much more easily achieve 3-2-1, by being 1 of the copies, on a different media AND in a different location. It’s a 3-2-1 rule slam dunk!
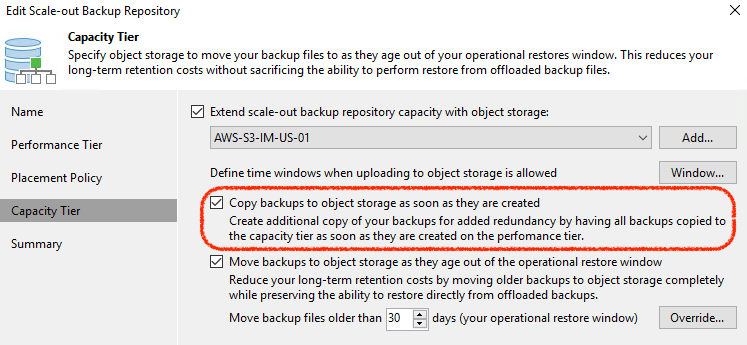
When used together, both Move and Copy policies complement each other perfectly to fully take advantage of object storage by keeping the local landing zone for quicker operational restore easier to manage from a data growth and capacity planning point of view. Copy mode then ensures that, in the case of disaster, there is a full copy of backup restore points available for recovery.
Ok, 3-2-1 is achieved faster and easier than ever. Check! Now, are you fully protected and 100% safe? Not yet. What about ransomware, hackers or malicious insiders?
Immutability – Your solution for ultimate protection.
Protection against malicious intent or accidental deletion of backup data has become critical in anyone’s data protection strategy– and with immutable backup functionality for Amazon S3 and S3-compatible object storage repositories, data that is shifted or copied into the Capacity Tier is further protected. This feature relies on the S3 API to set a period of time on each block of data uploaded to Object Storage where it cannot be modified or deleted by anybody. Yes, we mean anybody: intruders, malicious actors, accidental deletion by admins and more.
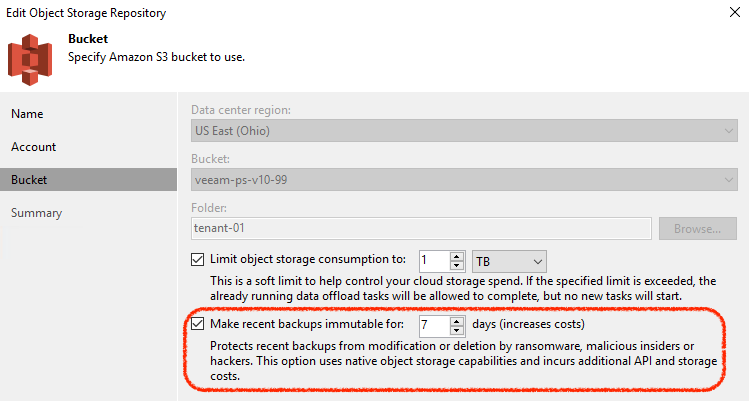
This effectively works to protect all recent (and generally most important) backup points until the set period has expired. And even having the highest-possible privileges on an AWS account does not provide you the ability to delete or modify the data, period.
As mentioned, immutable backups is a feature available for Amazon S3 and a variety of S3-compatible object storage providers including Ceph, Cloudian, Zadara and more. Check out the latest approved Veeam Ready “object” providers here for the latest and expect many more to come soon.
Now ransomware and inside threats are under control, but what if I lose the datacenter completely? We have a solution there too.
Enhanced Recoverability with Simplified Backup Import
The resiliency built into the Cloud Tier is such that if you totally lost your on-premises installation of Veeam Backup & Replication, you would be able to restore from data that was copied or moved into the object storage. This was true in the Update 4 release, but we have further improved the convenience and speed in which this data back be accessed after a disaster scenario has been triggered with the new Mount Object Storage Repository feature in v10.
With this feature, content in an existing object storage repository can be registered in a newly provisioned backup server (even running on a laptop and using Community Edition), and you can have the existing backup data points made available for restore operations in no time, including restores directly to the public cloud or instant recovery back to on-prem.
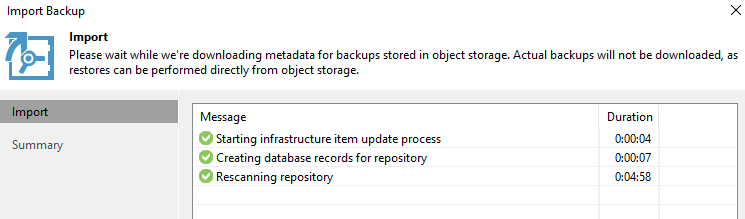
Unlike with the previous version, you no longer need to re-create and re-scan SOBR, because we make restore points available directly from the object storage by quickly downloading a very small amount of metadata during the most familiar Import Backup process. In other words, you can now import backups from object storage as quickly and easily as from local storage. How cool is that?
Conclusion
With these innovative additions to Veeam Cloud Tier, the abilities for customers to do off-site backup faster, store data for longer periods at lower costs, achieve 3-2-1 , and to recover quickly from a potential malicious attack or disaster scenario have been greatly enhanced. Not only are we now able to copy backups offsite for redundancy and longer term retention on object storage, but we are able to also have that data immutable, and easily recoverable with the new Import feature, leading to much lower RTOs.
This article was provided by our service partner : Veeam