Introduction
When you need to back up large amounts of data, you want to use up as little disk space as possible in order to minimize backup storage costs. However, with host-based image-level backups, traditional technologies force you to back up the entire virtual machine (VM) image, which presents multiple challenges that were never problems for classic agent-based backups.
For example, during backup analysis using Veeam ONE, you might notice that some VM backups are larger than the actual disk space usage in guest OS, resulting in higher-than-planned backup repository consumption. Most commonly, this phenomenon can be observed with file servers or other systems where a lot of data is deleted without being replaced with new data.
Another big sink for repository disk space consumption is useless files. While you might not need to back up data stored in certain files or directories in the first place, image-level backups force you to do this.
“Deleted” does not necessarily mean actually deleted
It is widely known that in vast majority of most modern file systems deleted files do not disappear from the hard drive completely. The file will only be flagged as deleted in the file allocation table (FAT) of the file system (e.g., the master file table (MFT) in case of NTFS). However, the file’s data will continue to exist on the hard drive until it is overwritten by a new file. This is exactly what makes tools like Undelete even possible. In order to reset the content of those blocks, you have to use tools like SDelete by Windows Sysinternals. This tool effectively overwrites the content of blocks belonging to deleted files with zeroes. Most backup solutions will then dedupe and/or compress these zeroed blocks so they do not take any extra disk space in the backup. However, running SDelete periodically on all your VMs is time consuming and hardly doable when you have hundreds of VMs, so most users simply don’t do this and allow blocks belonging to the deleted files to remain in the backup.
Another drawback of using SDelete is that it will inflate thin-provisioned virtual disks and will require you to use technologies such as VMware Storage vMotion to deflate them after SDelete processing. See VMware KB 2004155 for more information.
Finally, these tools must be used with caution. Because SDelete creates a very big zeroed file, you have to be careful not to affect other production applications on the processed server because that file is temporarily consuming all available free disk space on the volume.
Not backing up useless files in the first place
It goes without saying that there are certain files and directories that you don’t want to back up at all (e.g., application logs, application caches, temporary export files or user directories with personal files). There also might be data protection regulations in place that actually require you to exclude specific objects from backup. However, until today, the only way for most VM backup solutions to filter out useless data was to manually move useless data on every VM to the dedicated virtual drives (VMDK/VHDX) and exclude those virtual drives from processing. Again, because it’s simply not feasible to maintain this approach in large environments with dozens of new VMs appearing daily, most users simply accepted the need to back up useless data with image-based backups as a fact of life.
Meet Veeam BitLooker
Veeam BitLooker is the patent-pending data reduction technology from Veeam that allows the efficient and fully automated exclusion of deleted file blocks and useless files, thus enabling you to save considerable amount of backup storage and network bandwidth and further reduce costs.
The first part of BitLooker was introduced in Veeam Backup & Replication back a few years ago and enabled the exclusion of the swap file blocks from processing. Considering that each VM creates a swap file, which is usually at least 2 GB in size and changes daily, this is a considerable amount of data that noticeably affects full and incremental backup size. However, BitLooker automatically detects the swap file location and determines the blocks backing it in the corresponding VMDK. These blocks are then automatically excluded from processing, replaced with zeroed blocks in the target image and are not stored in a backup file or transferred to a replica image. The resulting savings are easy to see!
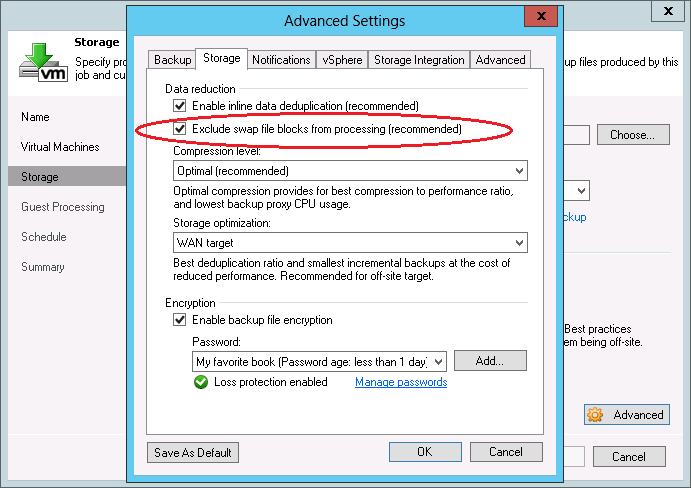
BitLooker in v9
In Veeam Backup & Replication v9, BitLooker’s capabilities have extended considerably in order to further improve data reduction ratios. In Veeam Backup & Replication v9, BitLooker has now three distinct capabilities:
- Excluding swap and hibernation files blocks
- Excluding deleted files blocks
- Excluding user-specified files and folders
In v9, BitLooker supports NTFS-formatted volumes only. Most of BitLooker is available right in the Veeam Backup & Replication Standard edition. However, excluding user-specified files and folders requires at least Enterprise edition.
Configuring BitLooker
There are a few options for controlling BitLooker in v9. You can find the first two in the advanced settings of each backup and replication job.
Note that the option to exclude swap file blocks was available in previous product versions, but it was enhanced in v9 to also exclude hibernation files.
Now, there is the new option that enables the exclusion of deleted file blocks:
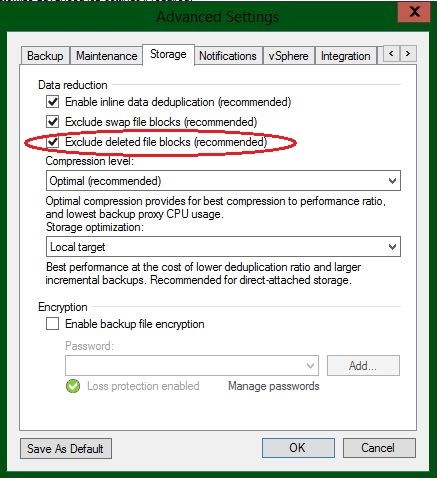
Users upgrading from previous versions will note that by default, deleted file blocks exclusion remains disabled for existing jobs after upgrading so it doesn’t not alter their existing behavior. You can enable it manually for individual jobs or automatically for all existing jobs with this PowerShell script.
In most cases, you should only expect to see minor backup file size reduction after enabling deleted file blocks exclusion. This is because in the majority of server workloads, data is never simply deleted, but rather always overwritten with new data. More often than not, it is replaced with more data than what was deleted, which is the very reason the world’s data almost doubles every 2 years. However, in certain scenarios (such as those involving data migrations), the gains can be quite dramatic.
Finally, in v9, BitLooker also allows you to configure the exclusion of specific files and folders for each backup job. Unlike previous options, this functionality is a part of the application-aware guest processing logic, and exclusions can only be performed on a running VM. Correspondingly, you can find the file exclusion settings in the advanced settings of guest processing step of the job wizard. You have the option to either exclude specific file system objects or, conversely, back up nothing but specific objects:
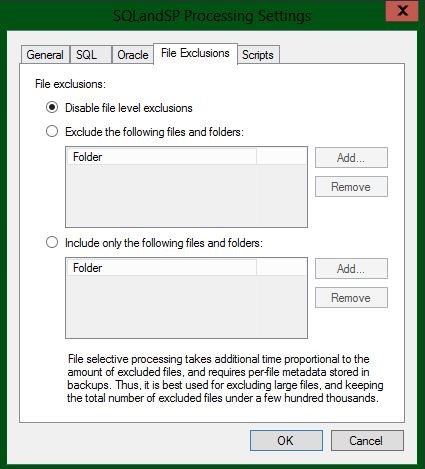
When using this functionality, keep in mind that it increases both VM processing time and memory consumption by the data mover, depending on the amount of excluded files. For example, if processing exclusions for 10,000 files takes less than 10 seconds and requires just 50MB of extra RAM, then excluding 100,000 files takes 2 minutes and requires almost 400MB of extra RAM.
Summary
Veeam BitLooker offers users the possibility to further reduce backup storage and network bandwidth consumption without incurring additional costs. Enabling this functionality takes just a few clicks, and the data reduction benefits can be enjoyed in the immediate backup or replication job run.
What results are you seeing after enabling BitLooker in v9? Please share your numbers in the comments!
Re-posted from : https://www.veeam.com/blog/save-backup-storage-using-veeam-backup-replication-bitlooker.html


