| By now, most of you have probably already heard of the biggest disaster in the history of IT – Meltdown and Spectre security vulnerabilities which affect all modern CPUs, from those in desktops and servers, to ones found in smartphones. Unfortunately, there’s much confusion about the level of threat we’re dealing with here, because some of the impacted vendors need reasons to explain the still-missing security patches. But even those who did release a patch, avoid mentioning that it only partially addresses the threat. And, there’s no good explanation of these vulnerabilities on the right level (not for developers), something that just about anyone working in IT could understand to make their own conclusion. So, I decided to give it a shot and deliver just that.
First, some essential background. Both vulnerabilities leverage the “speculative execution” feature, which is central to the modern CPU architecture. Without this, processors would idle most of the time, just waiting to receive I/O results from various peripheral devices, which are all at least 10x slower than processors. For example, RAM – kind of the fastest thing out there in our mind – runs at comparable frequencies with CPU, but all overclocking enthusiasts know that RAM I/O involves multiple stages, each taking multiple CPU cycles. And hard disks are at least a hundred times slower than RAM. So, instead of waiting for the real result of some IF clause to be calculated, the processor assumes the most probable result, and continues the execution according to the assumed result. Then, many cycles later, when the actual result of said IF is known, if it was “guessed” right – then we’re already way ahead in the program code execution path, and didn’t just waste all those cycles waiting for the I/O operation to complete. However, if it appears that the assumption was incorrect – then, the execution state of that “parallel universe” is simply discarded, and program execution is restarted back from said IF clause (as if speculative execution did not exist). But, since those prediction algorithms are pretty smart and polished, more often than not the guesses are right, which adds significant boost to execution performance for some software. Speculative execution is a feature that processors had for two decades now, which is also why any CPU that is still able to run these days is affected.
Now, while the two vulnerabilities are distinctly different, they share one thing in common – and that is, they exploit the cornerstone of computer security, and specifically the process isolation. Basically, the security of all operating systems and software is completely dependent on the native ability of CPUs to ensure complete process isolation in terms of them being able to access each other’s memory. How exactly is such isolation achieved? Instead of having direct physical RAM access, all processes operate in virtual address spaces, which are mapped to physical RAM in the way that they do not overlap. These memory allocations are performed and controlled in hardware, in the so-called Memory Management Unit (MMU) of CPU.
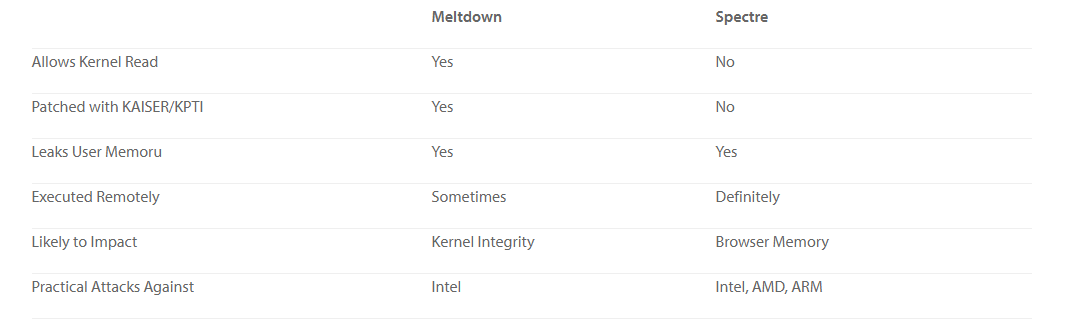
At this point, you already know enough to understand Meltdown. This vulnerability is basically a bug in MMU logic, and is caused by skipping address checks during the speculative execution (rumors are, there’s the source code comment saying this was done “not to break optimizations”). So, how can this vulnerability be exploited? Pretty easily, in fact. First, the malicious code should trick a processor into the speculative execution path, and from there, perform an unrestricted read of another process’ memory. Simple as that. Now, you may rightfully wonder, wouldn’t the results obtained from such a speculative execution be discarded completely, as soon as CPU finds out it “took a wrong turn”? You’re absolutely correct, they are in fact discarded… with one exception – they will remain in the CPU cache, which is a completely dumb thing that just caches everything CPU accesses. And, while no process can read the content of the CPU cache directly, there’s a technique of how you can “read” one implicitly by doing legitimate RAM reads within your process, and measuring the response times (anything stored in the CPU cache will obviously be served much faster). You may have already heard that browser vendors are currently busy releasing patches that makes JavaScript timers more “coarse” – now you know why (but more on this later).
As far as the impact goes, Meltdown is limited to Intel and ARM processors only, with AMD CPUs unaffected. But for Intel, Meltdown is extremely nasty, because it is so easy to exploit – one of our enthusiasts compiled the exploit literally over a morning coffee, and confirmed it works on every single computer he had access to (in his case, most are Linux-based). And possibilities Meltdown opens are truly terrifying, for example how about obtaining admin password as it is being typed in another process running on the same OS? Or accessing your precious bitcoin wallet? Of course, you’ll say that the exploit must first be delivered to the attacked computer and executed there – which is fair, but here’s the catch: JavaScript from some web site running in your browser will do just fine too, so the delivery part is the easiest for now. By the way, keep in mind that those 3rd party ads displayed on legitimate web sites often include JavaScript too – so it’s really a good idea to install ad blocker now, if you haven’t already! And for those using Chrome, enabling Site Isolation feature is also a good idea.
OK, so let’s switch to Spectre next. This vulnerability is known to affect all modern CPUs, albeit to a different extent. It is not based on a bug per say, but rather on a design peculiarity of the execution path prediction logic, which is implemented by so-called Branch Prediction Unit (BPU). Essentially, what BPU does is accumulating statistics to estimate the probability of IF clause results. For example, if certain IF clause that compares some variable to zero returned FALSE 100 times in a row, you can predict with high probability that the clause will return FALSE when called for the 101st time, and speculatively move along the corresponding code execution branch even without having to load the actual variable. Makes perfect sense, right? However, the problem here is that while collecting this statistics, BPU does NOT distinguish between different processes for added “learning” effectiveness – which makes sense too, because computer programs share much in common (common algorithms, constructs implementation best practices and so on). And this is exactly what the exploit is based on: this peculiarity allows the malicious code to basically “train” BPU by running a construct that is identical to one in the attacked process hundreds of times, effectively enabling it to control speculative execution of the attacked process once it hits its own respective construct, making one dump “good stuff” into the CPU cache. Pretty awesome find, right?
But here comes the major difference between Meltdown and Spectre, which significantly complicates Spectre-based exploits implementation. While Meltdown can “scan” CPU cache directly (since the sought-after value was put there from within the scope of process running the Meltdown exploit), in case of Spectre it is the victim process itself that puts this value into the CPU cache. Thus, only the victim process itself is able to perform that timing-based CPU cache “scan”. Luckily for hackers, we live in the API-first world, where every decent app has API you can call to make it do the things you need, again measuring how long the execution of each API call took. Although getting the actual value requires deep analysis of the specific application, so this approach is only worth pursuing with the open-source apps. But the “beauty” of Spectre is that apparently, there are many ways to make the victim process leak its data to the CPU cache through speculative execution in the way that allows the attacking process to “pick it up”. Google engineers found and documented a few, but unfortunately many more are expected to exist. Who will find them first?
Of course, all of that only sounds easy at a conceptual level – while implementations with the real-world apps are extremely complex, and when I say “extremely” I really mean that. For example, Google engineers created a Spectre exploit POC that, running inside a KVM guest, can read host kernel memory at a rate of over 1500 bytes/second. However, before the attack can be performed, the exploit requires initialization that takes 30 minutes! So clearly, there’s a lot of math involved there. But if Google engineers could do that, hackers will be able too – because looking at how advanced some of the ransomware we saw last year was, one might wonder if it was written by folks who Google could not offer the salary or the position they wanted. It’s also worth mentioning here that a JavaScript-based POC also exists already, making the browser a viable attack vector for Spectre.
Now, the most important part – what do we do about those vulnerabilities? Well, it would appear that Intel and Google disclosed the vulnerability to all major vendors in advance, so by now most have already released patches. By the way, we really owe a big “thank you” to all those dev and QC folks who were working hard on patches while we were celebrating – just imagine the amount of work and testing required here, when changes are made to the holy grail of the operating system. Anyway, after reading the above, I hope you agree that vulnerabilities do not get more critical than these two, so be sure to install those patches ASAP. And, aside of most obvious stuff like your operating systems and hypervisors, be sure not to overlook any storage, network and other appliances – as they all run on some OS that too needs to be patched against these vulnerabilities. And don’t forget your smartphones! By the way, here’s one good community tracker for all security bulletins (Microsoft is not listed there, but they did push the corresponding emergency update to Windows Update back on January 3rd).
Having said that, there are a couple of important things you should keep in mind about those patches. First, they do come with a performance impact. Again, some folks will want you to think that the impact is negligible, but it’s only true for applications with low I/O activity. While many enterprise apps will definitely take a big hit – at least, big enough to account for. For example, installing the patch resulted in almost 20% performance drop in the PostgreSQL benchmark. And then, there is this major cloud service that saw CPU usage double after installing the patch on one of its servers. This impact is caused due to the patch adding significant overhead to so-called syscalls, which is what computer programs must use for any interactions with the outside world.
Last but not least, do know that while those patches fully address Meltdown, they only address a few currently known attacks vector that Spectre enables. Most security specialists agree that Spectre vulnerability opens a whole slew of “opportunities” for hackers, and that the solid fix can only be delivered in CPU hardware. Which in turn probably means at least two years until first such processor appears – and then a few more years until you replace the last impacted CPU. But until that happens, it sounds like we should all be looking forward to many fun years of jumping on yet another critical patch against some newly discovered Spectre-based attack. Happy New Year! Chinese horoscope says 2018 will be the year of the Earth Dog – but my horoscope tells me it will be the year of the Air Gapped Backup. |