This article is aimed at giving you a smooth start with Veeam Backup & Replication. It includes some basic advice on the initial setup, and outlines the most common misconfigurations that we, at Veeam Support, find in clients’ infrastructures during our investigations.
Recommendations on Veeam backup modes
In most cases, forward incremental or forever forward incremental backup modes are recommended as the fastest ones. Forever forward incremental (no periodic full backup) requires less space and offers decent performance. Forward incremental requires more space, but is also more robust (because a backup chain is further divided in subchains by periodic full backup).
Reverse incremental backup method is our oldest backup method and consequently the slowest. Depending on the type of storage in use, it can be three or more times slower than other modes. With the reverse incremental backup, you get a full backup as the last point in the chain. This allows for faster restores in case the most recent point is used, but the difference is often negligible in comparison to a forward incremental chain (if its length is not unreasonably long, we usually suggest it to be around 30 days).
Insights on the full backup
Synthetic full operation builds a full backup file from the restore points already residing in your repository. However, not every storage type provides a good performance with synthetic operations, so we advise to use active full backup as an alternative.
When you set up a synthetic full backup mode, there is an additional “Transform previous backup chains into rollbacks” option available. Keep in mind though that this option starts a task of transforming incremental backups (.VIB) into rollbacks (.VRB), which is very laborious for your target backup repository. For example, it will help you transform your current chain into the reverse incremental one for archival purposes. However, if you use it as a main backup method, it would produce a very specific backup chain consisting of a full backup file and a mix of forward and reverse incremental restore points.
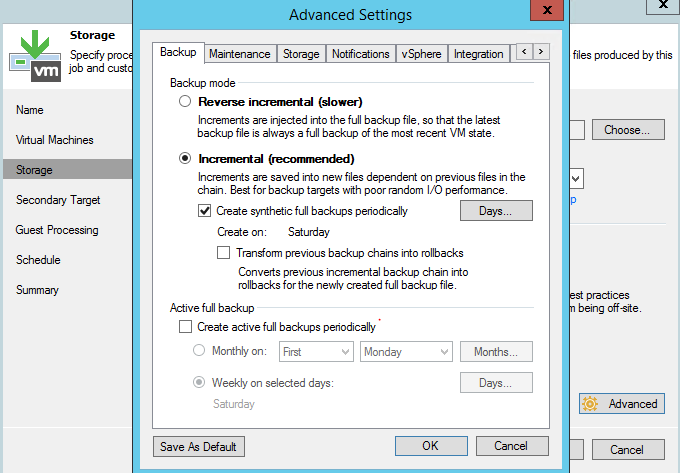
Figure 1. A forward incremental backup job with periodic synthetic full.
Guest processing tips
Guest processing is used to create consistent backups of your VMs. And if they run instances of Microsoft Exchange, Active Directory, SharePoint, SQL Server and Oracle applications, you will be able to leverage granular restores using Veeam Explorers. Please note that guest processing relies on a VSS framework (a Windows feature), which should be functioning correctly, otherwise your backup jobs will fail.
To enable guest processing, go to Guest Processing of backup job properties. You should enable “Application-aware processing” option and you should provide an administrative account under guest OS credentials.
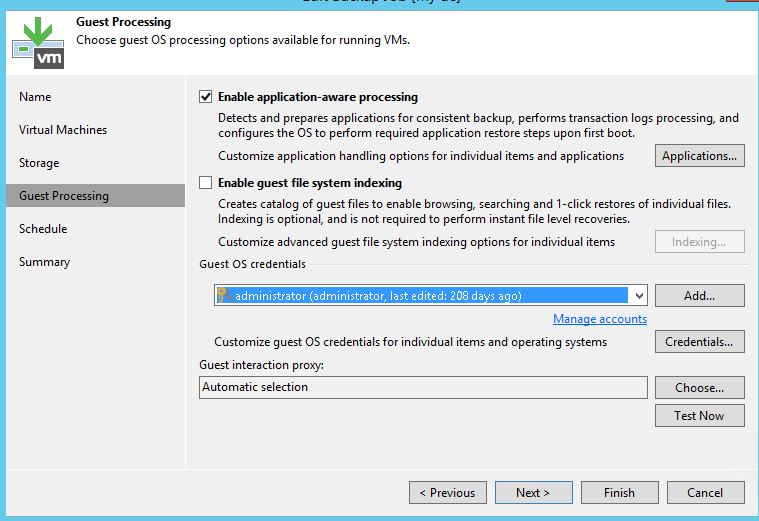
Figure 2. Guest processing step controls application-aware processing and indexing.
If some of VMs in the job require specific credentials, you can set them by clicking on the “Credentials” button. This brings up the Credentials menu. Click on “Set User…” to specify the credentials that should be used with the VM.
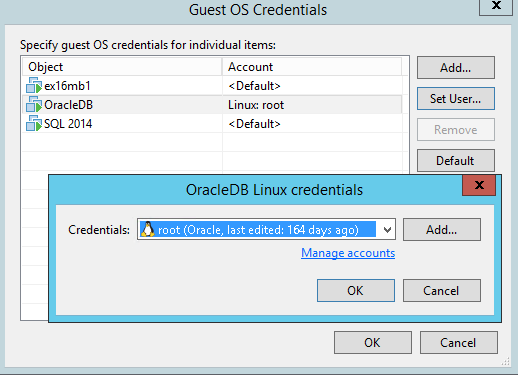
Figure 3. Credentials menu allows to set up users for each VM in the job.
Clicking on the “Applications…” button brings up a menu where you can specify options for supported applications and disable the guest processing for certain VMs, if needed.
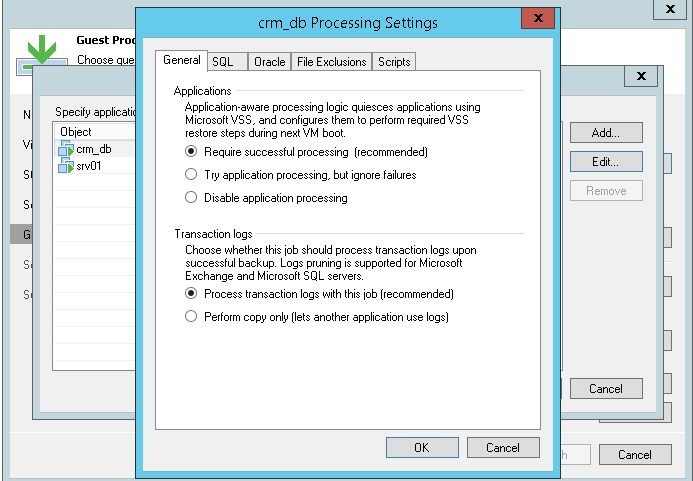
Figure 4. In Applications menu, you can specify options for various application or disable guest processing completely for a VM.
VM guest file system indexing
With “VM Guest File System Indexing” enabled, Veeam Backup & Replication creates a catalog of files inside the VM, allowing you to use guest file search and perform 1-click restores through our Veeam Backup Enterprise Manager.
In case you don’t use the Enterprise Manager, then you can cut some (sometimes significant) time off your backup window and save space on the C: drive of a Veeam server by disabling this option. It doesn’t affect your ability to perform file level restores from your Veeam Backup & Replication console.
Secondary backup destination
No storage vendor can guarantee an absolute data integrity. Veeam checks a backup file once it’s written to a disk, but, with millions of operations happening on the datastore, occasional bits may get swapped causing silent corruption. Veeam Backup & Replication provides features like SureBackup and health checks that help detect an early corruption. However, sometimes it may be already too late, so it’s absolutely necessary to follow the 3-2-1 rule and use different sets of media in several locations to guarantee data Availability.
To maintain the 3-2-1 rule, right after creating a primary backup job, it’s advised to set up a secondary copy job. This can be a Backup Copy Job to a secondary storage, Backup Copy Job to a cloud repository or a copy to tape.
Instant VM recovery as it should be
Instant VM Recovery allows you to start a VM in minimal time right from a backup file. However, you need to keep in mind that a recovered VM still sits in your backup repository and consumes its resources. To finalize the restore process, the VM must be migrated back to the production. Too often we at Veeam Support see critical VMs working for weeks in the Instant VM Recovery mode until a datastore fills up and data is lost.
For those of you looking for a deep dive on the topic, I recommend the recent blog post on Instant VM Recovery by Veeam Vanguard Didier Van Hoye.
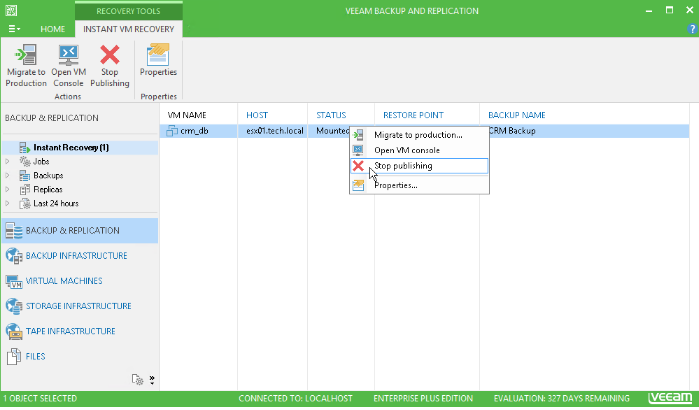
Figure 5. Soon after VM is started in the Instant VM Recovery mode you should initiate its migration back to the production.
Mind the CIFS as a main target repository
Veeam is storage agnostic and supports several types of backup repositories. Over the years, it was proven that a Windows or Linux physical server with internal storage gives the best performance in most cases.
Backup repository on a CIFS share still remains a popular choice, yet it generally offers the poorest performance of all options. Many modern NAS devices support iSCSI, so a better choice would be to create an iSCSI disk and present it to a Veeam server/proxy. Note though, that it’s also not recommended to use reverse incremental backup mode for repositories on NAS because it puts heavy IO load on the target.
Target proxy for replication
When replicating over the WAN, it is advised to deploy a backup proxy on the target site and configure it as a target proxy in replication job settings. This will create a robust channel between the two sites. We recommend setting a target proxy to NBD/Network mode, as using hot-add for replica can cause stuck and orphaned snapshots.
Note that when using WAN accelerators, a target proxy should still be deployed. Target WAN accelerator and target proxy can be installed on different or on a single machine, given it has enough resources.
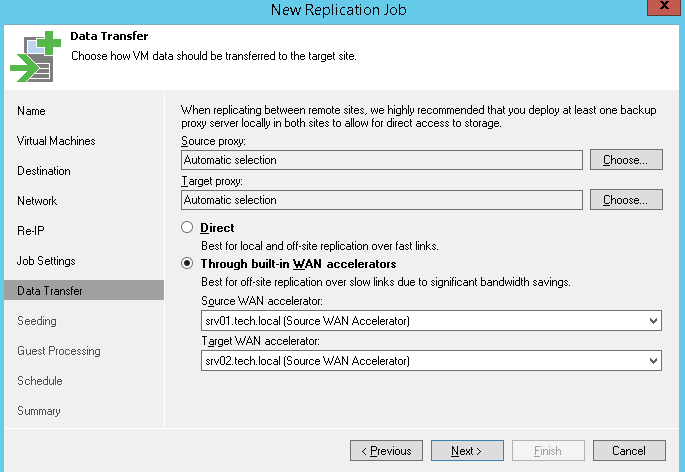
Figure 6. For replication over WAN, you should specify source and target proxy.
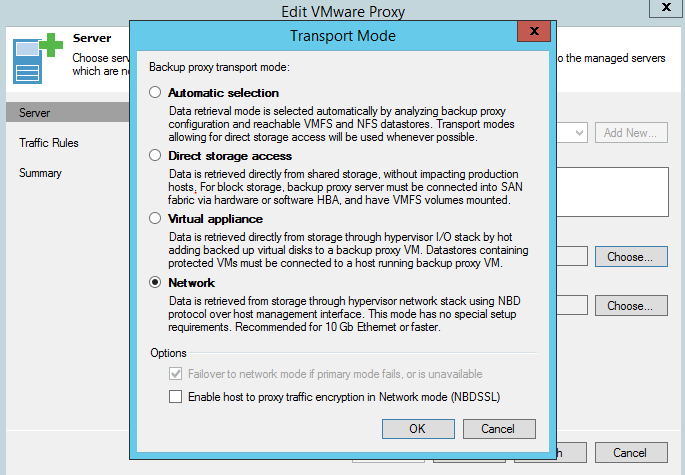
Figure 7. Set the target proxy mode to Network.
A must-do for a tape server
Tape server is a component responsible for communication with a tape device. It is installed on a physical machine to which a tape device is connected (“pass through” connections via ESXi host to a virtual machine are not supported!).
Veeam Backup & Replication gets the information about the library from the OS, so you should make sure that the latest drivers are installed and the tape device is visible correctly in the device manager.
You can find more info on using tapes with Veeam Backup & Replication in the previous blog post.
Social Media Malware is Deviant, Destructive
We’ve seen some tricky techniques used by cybercriminals to distribute malware through social media. One common threat begins with a previously compromised Facebook account sending deceptive messages that contain SVG image attachments via Facebook Messenger. (The SVG extention is an XML-based vector image format for two-dimensional graphics with support for interactivity and animation.)
Cybercriminals prefer this XML-based image as it allows dynamic content. This enables the criminals to add malicious JavaScript code right inside the photo itself—in this case, linking to an external site. Users who click on the image find themselves on a website posing as YouTube that pushes a popup to install a browser extension or add-on or to view a video. There are plenty of red flags here like the URL clearly not being YouTube.com, as well as the fact that YouTube does not require any extensions to view videos.
Facebook messenger spreading an SVG image containing a harmful script
An example of a fake YouTube page with malicious browser extension popup
Worm-like propagation
If a you were to install this extension, it will take advantage of your browser access to your Facebook account to secretly mass-message your friends with the same SVG image file—like a worm, this is how it spreads. Victims don’t need to have very many friends for this tactic to be successful at propagating. For instance, if you have over 100 friends, then you only need less than 1% of your friends to fall for this for the scam for it to continue to propagate.
To make matters worse, the extension also downloads Nemucod, a generic malware downloader generally used to download and install a variety of other threats. Usually the go-to threat is ransomware given it’s proven business model for criminals.
Social media managers at risk
Those who manage social media accounts on behalf of businesses are particularly at risk of advanced malware and other cyberattacks. Earlier this spring, a new Windows trojan dubbed Stresspaint was found hidden inside a fake stress-relief app and likely spread through email and Facebook spam campaigns to infect 35,000 users, according to researchers at Radware who discovered the malware.
Stresspaint was rather deviant in the way it stole Facebook account credentials and logged into accounts looking specifically for data such as “each user’s number of friends, whether the account manages a Facebook Page or not, and if the account has a payment method saved in its settings,” according to Bleeping Computer.
Allowing cybercriminals to gain control of brand social media accounts can carry grave consequences such as reputation damage, loss of confidential information, and deeper access into an organization’s network. Last year, HBO was humiliated on their social profiles when the notorious hacker group OurMine breached several the network’s accounts and posted messages before the company finally regained control of their logins.
Crypto users targeted
Following the recent trend in malware, sophisticated variants of existing strains are now aimed at cryptocurrency users. A malicious Google Chrome extension called FacexWorm, which spreads through Facebook Messenger, was found to have morphed with a new ability to hijack cryptocurrency transactions made on a host of popular online exchanges, according to Coindesk. This further underlines the importance of exercising caution with the information you share on social media to avoid being a target, particularly if you are a user of cryptocurrency.
Cryptocurrency scams are another common threat that spreads throughout social media. Twitter is particularly notorious an outbreak of crypto scam bots that pose as high-profile tech leaders and industry influencers. Learn more about this type scam in my previous post.
Don’t let your guard down
Given the nature of social networks, many are likely to consider themselves to be in the company of friends on sites like Facebook, Instagram and Twitter. However, this assumption can be dangerous when you begin to trust links on social sites more than you would in your email inbox or other websites. For instance, a simple bot-spam message on Twitter was able to grant a hacker access to a Pentagon official’s computer, according to a New York Times report published last year.
It’s wise to be wary of clicking on all links, even those sent by friends, family or professional connections, as compromised social media accounts are often used to spread scams, phishing, and other types of cyberattacks. After all, just one wrong click can lead to an avalanche of cyber woes, such as identity theft, data loss, and damaged devices.
This article was provided by our service partner : webroot.com
Veeam Availability Console U1 is now available
Managed service providers (MSPs) are playing an increasingly critical role in helping businesses of all sizes realize their digital transformation aspirations. The extensive offerings made available to businesses continue to allow them to shift day-to-day management onto you, the MSP, while allowing them to focus on more strategic initiatives. One of the most notable services being backup and recovery.
We introduced Veeam Availability Console in November 2017, a FREE, cloud-enabled management platform built specifically for service providers. Through this console, service providers can remotely manage and monitor the Availability of their customer’s virtual, physical and cloud-based workloads protected by Veeam solutions with ease. And, in just a few short months, we’ve seen incredible adoption across our global Veeam Cloud & Service Provider (VCSP) partner base, with overwhelmingly positive feedback.
Today, I’m happy to announce the General Availability (GA) of Veeam Availability Console U1, bringing with it some of the most hotly requested features to help further address the needs of your service provider business.
Enhanced Veeam Agent support
The initial release of Veeam Availability Console was capable of monitoring Veeam Agents deployed and managed by the service provider through Veeam Availability Console. New to U1 is the ability to achieve greater insights into your customer environments with new support that extends to monitoring and alarms for Veeam Agents that are managed by Veeam Backup & Replication. With this new capability, we’re enabling you to extend your monitoring services to even more Veeam customers that purchase their own Veeam Agents, but still want the expertise that you can bring to their business. And yes, this even includes monitoring support for Veeam Agent for Linux instances that are managed by Veeam Backup & Replication.
New user security group
VCSP partners wanting to delegate Veeam Availability Console access without granting complete control (like local administrator privileges) can now take advantage of the new operator role. This role permits access to everything within Veeam Availability Console essential to the remote monitoring and management of customer environments (you can even assign access to your employees on a company-by-company basis), but excludes access to Veeam Availability Console server configuration settings. Now you can assign access to Veeam Availability Console to your staff without exposing settings of the Veeam Availability Console server.
ConnectWise Manage integration
We’re introducing native integration with ConnectWise Manage. Through this new, seamless integration (available in the plugins library tab), the management, monitoring and billing of Veeam Availability Console-powered cloud backup and Disaster Recovery as a Service (DRaaS) can now be consolidated with your other managed service offerings into the single pane of glass that is ConnectWise Manage. This integration makes it easier and more efficient to expand your services portfolio while making administration of multiple, differing managed services much more efficient.
Matt Baldwin, President of Vertisys said, “This integration is exactly what my business needs to streamline our managed backup and DRaaS offering. The interface is clean and intuitive with just the right number of features. We project a yearly savings of 50 to 60 hours.”
Let’s take a closer look at some of the integration points between Veeam Availability Console and ConnectWise Manage.
Mapping companies
Firstly, the integration will help avoid a lot of manually intensive work by automatically synchronizing and mapping companies present in ConnectWise Manage with those in Veeam Availability Console. Automatic mapping is achieved through the company name. Before mapping is fully-complete, Veeam Availability Console allows you to check over what it’s automatically mapped before committing to the synchronization. If no match is found, mapping can be completed manually to an existing company or through the creation of a new company, with the option to send login credentials for the self-service customer portal, too.
Ticket creation
The integration also enables you to more quickly resolve issues before they impact your customers’ business through automatic ticket creation within ConnectWise Manage from Veeam Availability Console alarms. You can specify from the list of available alarms within Veeam Availability Console all those that are capable of triggering a ticket (e.g. failed backup, exceeding quota, etc.), and to which service board within ConnectWise Manage the ticket is posted. We’ve also enabled you with the capability to set delays (e.g. 1 minute, 5 minutes, 15 minutes, etc.) between the alarm occurring and the ticket posting, so issues like a temporary connectivity loss that self-resolves doesn’t trigger a ticket immediately. Every ticket created in ConnectWise Manage is automatically bundled with the corresponding configuration, such as representing a computer managed by Veeam Availability Console. This makes it incredibly easy for support engineers to find which component failed and where to go fix it. The integration also works in reverse, so that when tickets are closed within ConnectWise Manage, the corresponding alarm in Veeam Availability Console will be resolved.
Billing
The final part of the integration extends to billing, reducing complexities for you and your customers by consolidating invoices for all the managed services in your portfolio connected to ConnectWise Manage into a single bill. Not only this, but the integration allows for the automatic creation of new products in ConnectWise Manage, or mapping to existing ones. Service providers can select which agreement Veeam Availability Console-powered services should be added to on a per-customer basis, with agreements updated automatically based on activity, quota usage, etc.
Enhanced scalability
Finally, we’ve enhanced the scalability potential of Veeam Availability Console, enabling you to deliver your services to even more customers. The scalability improvements specifically align to the supported number of managed Veeam Backup & Replication servers, and this is especially useful when paired with the enhanced Veeam Agent support discussed earlier. This ensures optimal operation and performance when managing up to 10,000 Veeam Agents and up to 600 Veeam Backup & Replication servers, protecting 150-200 VMs and Veeam Agents each.
This article was provided by our service partner : veeam.com
3 MSP Best Practices for Protecting Users
Cyberattacks are on the rise, with UK firms being hit, on average, by over 230,000 attacks in 2017. Managed service providers (MSPs) need to make security a priority in 2018, or they will risk souring their relationships with clients. By following 3 simple MSP best practices consisting of user education, backup and recovery, and patch management, your MSP can enhance security, mitigate overall client risk, and grow revenue.
User Education
An effective anti-virus is essential to keeping businesses safe; however, It isn’t enough anymore. Educating end users through security awareness training can reduce the cost and impact of user-generated infections and breaches, while also helping clients meet the EU’s new GDPR compliance requirements. Cybercriminals’ tactics are evolving and increasingly relying on user error to circumvent security protocols. Targeting businesses through end users via social engineering is a rising favorite among new methods of attack.
Common social engineering attacks include:
Highly topical, relevant, and timely real-life educational content can minimize the impact of security breaches caused by user error. By training clients on social engineering and other topics including ransomware, email, passwords, and data protection, you can help foster a culture of security while adding serious value for your clients.
Backup and Disaster Recovery Plans
It’s important for your MSP to stress the importance of backups. If hit with ransomware without a secure backup, clients face the unsavory options of either paying up or losing important data. Offering clients automated, cloud-based backup makes it virtually impossible to infect backup data and provides additional benefits, like a simplified backup process, offsite data storage, and anytime/anywhere access. In the case of a disaster, there should be a recovery plan in place. Even the most secure systems can be infiltrated. Build your plan around business-critical data, a disaster recovery timeline, and protocol for disaster communications.
Things to consider for your disaster communications
Once a plan is in place, it is important to monitor and test that it has been implemented effectively. A common failure with a company’s backup strategy occurs when companies fail to test their backups. Then, disaster strikes and only then do they discover they cannot restore their data. A disaster recovery plan should be tested regularly and updated as needed. Once a plan is developed, it doesn’t mean that it’s effective or set in stone.
Patch Management
Consider it an iron law; patch and update everything immediately following a release. As soon as patches/updates are released and tested, they should be applied for maximum protection. The vast majority of updates are security related and need to be kept up-to-date. Outdated technology–especially an operating system (OS)–is one of the most common weaknesses exploited in a cyberattack. Without updates, you leave browsers and other software open to ransomware and exploit kits. By staying on top of OS updates, you can prevent extremely costly cyberattacks. For example, in 2017 Windows 10 saw only 15% of total files deemed to be malware, while Windows 7 saw 63%. These figures and more can be found in Webroot’s 2018 Threat Report.
Patching Process
Patching is a never-ending cycle, and it’s good practice to audit your existing environment by creating a complete inventory of all production systems used. Remember to standardize systems to use the same operating systems and application software. This makes the patching process easier. Additionally, assess vulnerabilities against inventory/control lists by separating the vulnerabilities that affect your systems from those that don’t. This will make it easier for your business to classify and prioritize vulnerabilities, as each risk should be assessed by the likelihood of the threat occurring, the level of vulnerability, and the cost of recovery. Once it’s determined which vulnerabilities are of the highest importance, develop and test the patch. The patch should then deploy without disrupting uptime—an automated patch system can help with the process.
Follow these best practices and your MSP can go a lot further toward delivering the security that your customers increasingly need and demand. Not only you improve customer relationships, but you’ll also position your MSP as a higher-value player in the market, ultimately fueling growth. Security is truly an investment MSPs with an eye toward growth can’t afford to ignore.
This article was provided by our service partner : Webroot
How to build a disaster recovery plan with Veeam
Here’s a true story from one of our customers. A gas explosion resulted in a major power failure downtown, which in turn left the company’s primary data center offline for a week. This is a classic example of an IT Disaster – unexpected and unpredictable, disrupting business continuity and affecting Always-On operations. We can only imagine how much it could cost that company to stay offline for a week (as much as losing their business, I’d say), if they didn’t have a reliable disaster recovery plan and an Availability solution to execute this plan.
A solid disaster recovery plan makes your company resilient to IT disruptions and able to restore your services in case of disaster with minimal to no impact on users and business operations. It’s not just making regular backups, but a complex IT infrastructure assessment and documenting (including hardware, software, networks, power and facilities), business impact analysis of applications and workloads and planning on staff, roles and risk assessment. And above all, there’s an essential testing and exercising of your disaster recovery plan. If you don’t test, how would you know that it works as expected?
Unlike physical infrastructures with all their complexity, virtualization gives more flexibility in management and processes allowing you to do more with less. For virtualized data centers, Veeam delivers joint capabilities of enabling data Availability and infrastructure management. By using Veeam Availability Suite, you cover multiple points in your DR plan at once and get:
These also address compliance audit needs by providing you with up-to-date information on backed-up workloads, backups reliability and actual data recovery time versus your SLAs. If staying compliant and ready for audits is important for you, I recommend you read the new white paper by Hannes Kasparick, Mastering compliance, audits and disaster recovery planning with Veeam.
Replication as a core disaster recovery technology
DR planning includes defining the lowest possible RTO to minimize the disruption of business operations. In terms of ability to restore failed operations in minutes, replication mechanism wins the game allowing you to instantly switch the failed workload to its ready-to-use “clone” to get the lowest-possible RTO. For DR purposes, standby replicas of production VMs are stored on a remote secondary site or in the cloud. Even if the production site goes down, like in my example with a major power failure, a remote site remains unaffected by the disaster and can take the load.
Test your disaster recovery plan!
All data security and management standards (ISO family is not an exception) imply DR plan testing as a mandatory exercise. You can never know if everything will work as expected in cases of real disasters until you try it and run the planned procedures in advance. DR simulation will also allow you to ensure that your personnel are well-prepared for extreme IT situations and everyone mentioned in your DR plan is aware of the activities they need to perform. If you discover any drawbacks during DR testing – either human or software-related – you’ll have a good chance to fix your DR plan accordingly and thus potentially avoid serious disruptions in your business continuity.
Automated recovery verification for backups and replica restore points built in Veeam Backup & Replication (for no additional fees!) will save you much time and additional resources for testing. SureReplica allows to boot replicated VMs (VMware only for v9) to the necessary restore point in an isolated Virtual Lab and automatically perform heartbeat, ping and application tests against them. Also, you have an option to run your own customized tests – all without any impact on your production.
Final word
Disaster recovery planning is not just another bureaucracy, but a set of measures to maintain an organization’s business continuity. Built in compliance with international regulations and standards, a DR plan gives your customers a high level of confidence in your non-stop services, data security and Availability. Veeam helps you to stay compliant with both internal and external IT regulations, be ready for audit and be able to restore any system or data in minutes.
This article was provided by our service partner : veeam.com
Defining the Value of Technology Teams
Technology Teams are made up of a lot more than just the service technicians working with your customers. Every Technology Team is made up of a combination of people that account for every step of the Customer Journey. Sales, finance, even marketing…they’re all a part of your Technology Teams and enable you to reach your clients, making their jobs and lives a little easier and helping you stay ahead of technology.
Technology Teams are formed to deliver a unique set of solutions and services. Within one company, multiple Technology Teams can combine to form a resilient Technology Organization. ConnectWise provides a tailored experience to fit the customer journey by turning the ConnectWise suite into a platform of microservices. Building on the foundation of the Solutions Menu, we will focus on Technology Workers.
Building Value
As a business with your sights set on current and future success, you have to find ways to build resiliency into your business. A key way to do this is by building out multiple Technology Teams to continuously increase and diversify the value you offer to your clients. The more you can do to cover their needs, now and into the future, the more you’ll be able to serve the needs of your current customers and attract new ones.
Get Specialized
So why not just have one big team in your company, with every resource managing all of the information they need for each customer’s needs? Every Technology Team is going to have a unique approach to solving customer problems, whether in sales, services or billing, and you’ll want to have people dedicated to making sure those unique approaches are supported. Instead of overwhelming your team with the heavy load of understanding everything about every one of your customers.
No one can be a master of everything, so allow your Technology Teams to focus only on expertise in their specific area. By dividing your business efforts to focus on each specific Technology Team, you’ll be more efficient, your team will feel more in control, and your customers will feel like you really understand their needs.
Take the Lead
Once your Technology Teams are leading the way in meeting your customers’ varied—and growing—needs, they’ll be responsible for guiding your customers through every part of the customer journey.
Mastering each step of the customer journey for each Technology Team enables them to provide excellent customer service, laying the groundwork for long-term relationships that keep your customers happy and loyal.
Where to Start
Fortunately, you’re probably already doing this without realizing it. Do you have a list of services you offer? Those probably line up pretty nicely to some of the Technology Teams already. Now you’ll just need to conduct a gap analysis to find out what you’ve got covered and what still needs to have resources put toward it.
A gap analysis looks at your current performance to help you pinpoint the difference between your current and ideal states of business. Get started by answering these three deceptively simple questions with input from your team:
Keep working toward full coverage for every Technology Team your customers are looking for, and seeing every client through the steps of the customer journey and before long, you’ll be meeting and exceeding your business goals.
This article was provided by our service partner : Connectwise
Automating Employee Onboarding in Active Directory
Employee onboarding is a task that is ripe for automation. Spend any time in the tech industry and you know that Active Directory (AD) helps improve workflow and operational services. In other words, it’s critical to an IT organization. When hired, every employee should be given an Active Directory user account, an email mailbox, access to various operating systems, a home folder with specific permissions available only to them, and so on.
However, AD is a big part of employee onboarding that many organizations are still doing manually. In many companies, the helpdesk is still manually opening Active Directory Users & Computers, creating a new user, and adding that user to a specific set of groups. This ultimately increases the risk of messing up that person’s other responsibilities within their account. Again, this is something automation can alleviate! And this is where Kennected comes in. Because staff onboarding is one of those tasks that’s performed hundreds of times and rarely changes, it’s a perfect candidate for automation even used for dbs check.
So, how do you go about automating onboarding in AD?
One of the easiest ways to automate AD tasks is with PowerShell – an automating management structure. By using a freely available PowerShell module, you can create scripts to do just about anything with AD.
For our purposes, we need to create a script to make a new user account for an employee and potentially add it to a few common groups. To do this, download a copy of Remote Server Administration Tools (RSAT) which will give you the Active Directory PowerShell module. Once you do this, ensure you’re on a company domain-joined computer and that you have the appropriate rights to create new users.
In the Active Directory PowerShell module, there is a command called “New-AdUser.” There are lots of ways to use this command but below is one of the most common ways. In this PowerShell code, we’ll generate a random password and then use it along with a first name, last name and username to create a new AD user.
Here’s an example of what this code looks like:
That’s it! No mouse clicking involved.
Once the above actions have been completed, we can move on to another useful AD onboarding command called “Add-AdGroupMember.” This will add the user that was just created to a few groups in a single line:
One of the great things about automating employee onboarding with PowerShell is that once the code is built, it can be used for one – or even one hundred – employees with no extra effort.
For example, perhaps you have a ton of new employees you need provision for in AD. By using the “Import-CSV” command, you can read each row in that CSV file and run the code we just went over.
This example assumes you have a CSV with the columns “FirstName” and “LastName.”
Here it is exemplified below:
These are only a few of the many user onboarding tools available when you automate employee onboarding in Active Directory. If your organization has a predefined process with specific rules that must be followed, this could be just the beginning of a much larger employee onboarding process that can be 100% automated.
This article was provided by our service partner Connectwise.
GDPR
As the EU’s General Data Protection Regulation (GDPR) edges closer, we’re looking back on the five most significant stories during the lead up to its implementation. Read about GDPR’s impact on data security and find out how to get prepared with five steps to compliance.
What aspect of GDPR will have the biggest impact on you or your business? Let us know in the comments below!
GDPR Myths
On April 14, 2016, the EU received its final legislative approval for GDPR, making the changes official as of May 25, 2018. Many myths surround the legislation, stirring confusion among those affected. One major myth is that GDPR compliance is focused on a fixed point in time, similar to the Y2K bug. However, GDPR will be an ongoing journey that requires a complete change to many company procedures. The regulation will begin in May 2018, so businesses may not be pleased to discover they are currently in the “grace period,” and there will not be another one after the implementation date.
Data Breached
We discovered in 2017 that many corporations are far too negligent when it comes to securely storing sensitive consumer data. It seemed like hardly a week passed without another major data breach making headlines. The year saw Equifax fall victim to the largest data breach in corporate history, Uber conceal a breach affecting 57 million users for over a year, and more than a million patients’ records stolen from the NHS’s database, to name just a few high profile cases. GDPR will not stop data breaches entirely, but the introduction of fines as high as €20 million, or 4% of annual turnover, for noncompliance should force companies to take their data responsibilities more serious.
Brexit
Britain’s decision to exit the European Union has added confusion concerning GDPR compliance for companies within the UK. In September, however, the UK updated their data protection legislation, which brings GDPR wholesale into UK law. This confirms that the UK also recognises the importance of data protection and suggests UK companies will need to be at least as careful as their EU peers. Also, any company dealing with EU citizen data (even those located outside of the EU), will be expected to comply with these standards.
Google and the Right to be Forgotten
Google received 2.4 million takedown requests under the EU’s updated ‘right to be forgotten’ laws, which have been in place for search engines since 2014. GDPR will now expand on this right to certain data subjects- giving people more control over deletion of their data once it’s no longer necessary for a company to have. Data subject rights have been enhanced, so companies that process personal data will be expected to have procedures in place to act on requests in the proscribed timeframes.
Facebook
Facebook have been in the news a lot over data rights, most recently for allegedly allowing Cambridge Analytica to harvest the data of more than 50 million Facebook users. Previously, the ICO had gotten WhatsApp to sign an undertaking in which it committed publicly to not share personal data with its parent company Facebook until the two services could do it in a GDPR-compliant way. GDPR is clearly bearing down on big companies that have been negligent with customer data previously.
How to get prepared
Are you prepared for GDPR? A company can take the following steps to help become GDPR-ready:
‘Smishing’: SMS and the Emerging Trend of Scamming Mobile Users via Text Messages
Text messages are now a common way for people to engage with brands and services, with many now preferring texts over email using whatsapp and many other apps, if you want to customized your app and get a few extra benefits download whatsapp mods here. But today’s scammers have taken a liking to text messages or smishing, too, and are now targeting victims with text message scams sent via shortcodes instead of traditional email-based phishing attacks.
What do we mean by shortcodes
Businesses typically use shortcodes to send and receive text messages with customers. You’ve probably used them before—for instance, you may have received shipping information from FedEx via the shortcode ‘46339’. Other shortcode uses include airline flight confirmations, identity verification, and routine account alerts. Shortcodes are typically four to six digits in the United States, but different countries have different formats and number designations.
The benefits of shortcodes are fairly obvious. Texts can be more immediate and convenient, making it easier for customers to access links and interact with their favorite brands and services. One major drawback, however, is the potential to be scammed by a SMS-based phishing attack, or ‘Smishing’ attack. (Not surprisingly given the cybersecurity field’s fondness for combining words, smishing is a combination of SMS and phishing.)
All the Dangers of Phishing Attacks, Little of the Awareness
The most obvious example of a smishing attack is a text message containing a link to mobile malware. Mistakenly clicking on this type of link can lead to a malicious app being installed on your smartphone. Once installed, mobile malware can be used to log your keystrokes, steal your identity, or hold your valuable files for ransom. Many of the traditional dangers in opening emails and attachments from unknown senders are the same in smishing attacks, but many people are far less familiar with this type of attack and therefore less likely to be on guard against it.
Smishing for Aid Dollars
Another possible risk in shortcodes is that sending a one-word response can trigger a transaction, allowing a charge to appear on your mobile carrier’s bill. When a natural disaster strikes, it is common for charities to use shortcodes to make it incredibly easy to donate money to support relief efforts. For instance, if you text “PREVENT” to the shortcode 90999, you will donate $10 USD to the American Red Cross Disaster Relief Fund.
But this also makes it incredibly easy for a scammer to tell you to text “MONSOON” to a shortcode number while posing as a legitimate organization. These types of smishing scams can lead to costly fraudulent charges on your phone bill, not to mention erode aid agencies ability to solicit legitimate donations from a wary public. A good resource for determining the authenticity of a shortcode in the United States is the U.S. Short Code Directory. This site allows you to look up brands and the shortcodes they use, or vice versa.
Protect yourself from Smishing Attacks
While a trusted mobile security app can help you stay protected from a variety of mobile threats, avoiding smishing attacks demands a healthy dose of cyber awareness. Be skeptical of any text messages you receive from unknown senders and assume messages are risky until you are sure you know the sender or are expecting the message. Context is also very important. If a contact’s phone is lost or stolen, that contact can be impersonated. Make sure the message makes sense coming from that contact.
This article was provided by our service partner : webroot.com
3 Surprising Keys to Success as a Technology Service Provider
A successful Technology Service Provider (TSP) knows that in this booming economy, they must bring their “A-Game” to the table in order to grow and succeed. Similar to sports, true professionals know that it’s the dedication to excellence and the refinement of the little things that can deliver a huge advantage. Let’s take a quick look at the three areas of your Technology Service Provider operational game plan that can benefit greatly from one simple, and many times overlooked, solution–IT certifications and IT skills training for your team.
New Business Development
Having certified engineers can have a great impact on your ability to attract and close new business. To your prospects, IT certifications are strong indicators that you are committed to delivering the most up-to-date, highest quality service and expertise.
Operational Efficiency
Your company simply runs better when your techs are well trained and certified. Trained engineers are your key to operational efficiency and customer retention. In addition, certifications also lead you down the path of increased profits too.
Employee Retention
Keeping your top engineers is the third key to Technology Service Provider prosperity. As the economy heats up and IT jobs become more abundant, you need a plan to retain your best engineers. Retention and job satisfaction are not just about salary and bonuses. True IT professionals are eager to learn and will respect and remain loyal to the organization that helps keep them on top of their IT skills and certifications.
This article was provided by our service partner : Connectwise
How to avoid typical misconfigurations when setting up Veeam
This article is aimed at giving you a smooth start with Veeam Backup & Replication. It includes some basic advice on the initial setup, and outlines the most common misconfigurations that we, at Veeam Support, find in clients’ infrastructures during our investigations.
Recommendations on Veeam backup modes
In most cases, forward incremental or forever forward incremental backup modes are recommended as the fastest ones. Forever forward incremental (no periodic full backup) requires less space and offers decent performance. Forward incremental requires more space, but is also more robust (because a backup chain is further divided in subchains by periodic full backup).
Reverse incremental backup method is our oldest backup method and consequently the slowest. Depending on the type of storage in use, it can be three or more times slower than other modes. With the reverse incremental backup, you get a full backup as the last point in the chain. This allows for faster restores in case the most recent point is used, but the difference is often negligible in comparison to a forward incremental chain (if its length is not unreasonably long, we usually suggest it to be around 30 days).
Insights on the full backup
Synthetic full operation builds a full backup file from the restore points already residing in your repository. However, not every storage type provides a good performance with synthetic operations, so we advise to use active full backup as an alternative.
When you set up a synthetic full backup mode, there is an additional “Transform previous backup chains into rollbacks” option available. Keep in mind though that this option starts a task of transforming incremental backups (.VIB) into rollbacks (.VRB), which is very laborious for your target backup repository. For example, it will help you transform your current chain into the reverse incremental one for archival purposes. However, if you use it as a main backup method, it would produce a very specific backup chain consisting of a full backup file and a mix of forward and reverse incremental restore points.
Figure 1. A forward incremental backup job with periodic synthetic full.
Guest processing tips
Guest processing is used to create consistent backups of your VMs. And if they run instances of Microsoft Exchange, Active Directory, SharePoint, SQL Server and Oracle applications, you will be able to leverage granular restores using Veeam Explorers. Please note that guest processing relies on a VSS framework (a Windows feature), which should be functioning correctly, otherwise your backup jobs will fail.
To enable guest processing, go to Guest Processing of backup job properties. You should enable “Application-aware processing” option and you should provide an administrative account under guest OS credentials.
Figure 2. Guest processing step controls application-aware processing and indexing.
If some of VMs in the job require specific credentials, you can set them by clicking on the “Credentials” button. This brings up the Credentials menu. Click on “Set User…” to specify the credentials that should be used with the VM.
Figure 3. Credentials menu allows to set up users for each VM in the job.
Clicking on the “Applications…” button brings up a menu where you can specify options for supported applications and disable the guest processing for certain VMs, if needed.
Figure 4. In Applications menu, you can specify options for various application or disable guest processing completely for a VM.
VM guest file system indexing
With “VM Guest File System Indexing” enabled, Veeam Backup & Replication creates a catalog of files inside the VM, allowing you to use guest file search and perform 1-click restores through our Veeam Backup Enterprise Manager.
In case you don’t use the Enterprise Manager, then you can cut some (sometimes significant) time off your backup window and save space on the C: drive of a Veeam server by disabling this option. It doesn’t affect your ability to perform file level restores from your Veeam Backup & Replication console.
Secondary backup destination
No storage vendor can guarantee an absolute data integrity. Veeam checks a backup file once it’s written to a disk, but, with millions of operations happening on the datastore, occasional bits may get swapped causing silent corruption. Veeam Backup & Replication provides features like SureBackup and health checks that help detect an early corruption. However, sometimes it may be already too late, so it’s absolutely necessary to follow the 3-2-1 rule and use different sets of media in several locations to guarantee data Availability.
To maintain the 3-2-1 rule, right after creating a primary backup job, it’s advised to set up a secondary copy job. This can be a Backup Copy Job to a secondary storage, Backup Copy Job to a cloud repository or a copy to tape.
Instant VM recovery as it should be
Instant VM Recovery allows you to start a VM in minimal time right from a backup file. However, you need to keep in mind that a recovered VM still sits in your backup repository and consumes its resources. To finalize the restore process, the VM must be migrated back to the production. Too often we at Veeam Support see critical VMs working for weeks in the Instant VM Recovery mode until a datastore fills up and data is lost.
For those of you looking for a deep dive on the topic, I recommend the recent blog post on Instant VM Recovery by Veeam Vanguard Didier Van Hoye.
Figure 5. Soon after VM is started in the Instant VM Recovery mode you should initiate its migration back to the production.
Mind the CIFS as a main target repository
Veeam is storage agnostic and supports several types of backup repositories. Over the years, it was proven that a Windows or Linux physical server with internal storage gives the best performance in most cases.
Backup repository on a CIFS share still remains a popular choice, yet it generally offers the poorest performance of all options. Many modern NAS devices support iSCSI, so a better choice would be to create an iSCSI disk and present it to a Veeam server/proxy. Note though, that it’s also not recommended to use reverse incremental backup mode for repositories on NAS because it puts heavy IO load on the target.
Target proxy for replication
When replicating over the WAN, it is advised to deploy a backup proxy on the target site and configure it as a target proxy in replication job settings. This will create a robust channel between the two sites. We recommend setting a target proxy to NBD/Network mode, as using hot-add for replica can cause stuck and orphaned snapshots.
Note that when using WAN accelerators, a target proxy should still be deployed. Target WAN accelerator and target proxy can be installed on different or on a single machine, given it has enough resources.
Figure 6. For replication over WAN, you should specify source and target proxy.
Figure 7. Set the target proxy mode to Network.
A must-do for a tape server
Tape server is a component responsible for communication with a tape device. It is installed on a physical machine to which a tape device is connected (“pass through” connections via ESXi host to a virtual machine are not supported!).
Veeam Backup & Replication gets the information about the library from the OS, so you should make sure that the latest drivers are installed and the tape device is visible correctly in the device manager.
You can find more info on using tapes with Veeam Backup & Replication in the previous blog post.